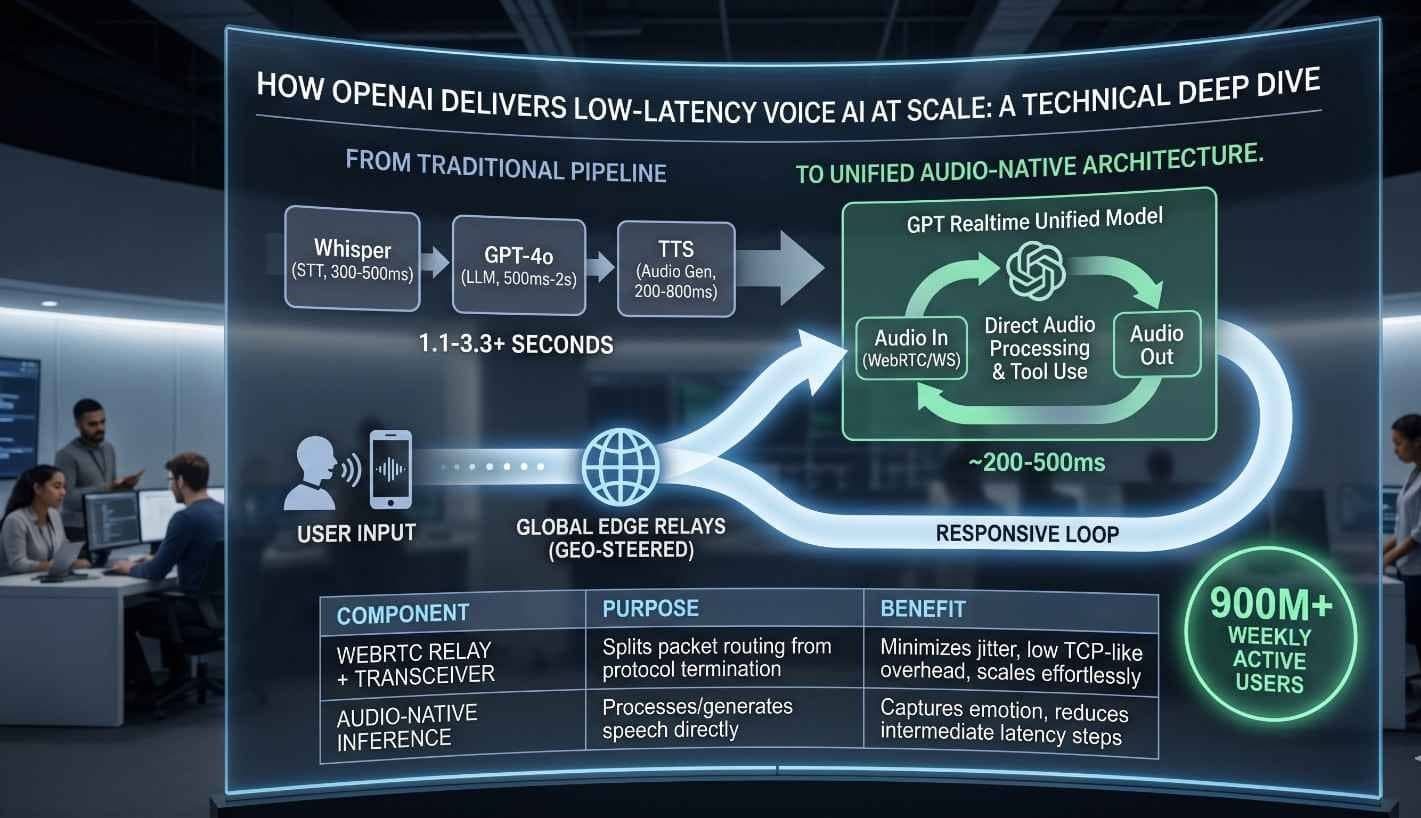
The architectural evolution of real-time artificial intelligence has reached a critical inflection point where the latency of machine-to-human interaction now rivals natural human conversational speeds. Traditionally, voice-enabled AI was characterized by a “cascaded” or “pipeline” approach, which concatenated discrete models for automatic speech recognition (ASR), text processing via a large language model (LLM), and text-to-speech (TTS) synthesis. This fragmented methodology introduced significant serialized delays, often exceeding two to three seconds, and fundamentally stripped the audio signal of its expressive nuances, such as emotional tone, prosody, and non-verbal cues. The introduction of OpenAI’s GPT-4o has revolutionized this paradigm by employing a natively multimodal architecture that processes text, audio, and vision within a single transformer pass. This technical deep dive explores the infrastructure, inference engineering, and global networking strategies that enable OpenAI to deliver these low-latency voice interactions to more than 900 million weekly active users while maintaining a response time as low as 232ms.
The Native Multimodal Real-Time AI
The fundamental breakthrough in reducing voice AI latency lies in the architectural transition from modular pipelines to unified multimodal transformers. In a traditional system, the ASR component would transcribe audio into text, often losing the “who” and the “how” of the speech in the process. The LLM would then generate a text response, which was finally passed to a TTS engine to be converted back into audio. Each step in this sequence acted as a technical bottleneck. In contrast, native multimodality allows a single model to “hear” the audio tokens directly and “speak” them back, preserving the continuity of the signal and enabling the model to respond to interruptions and emotional shifts in real time.
This native approach is supported by a significant expansion in tokenization efficiency. OpenAI’s o200k_base tokenizer, for instance, has a vocabulary size of roughly 200,000 tokens, representing a massive leap from the 50,000 tokens of GPT-2. This increased density allows for more efficient encoding of diverse inputs, including multilingual speech and complex audio patterns, without the computational explosion that would occur if the model processed raw characters or individual audio samples. By treating audio as a first-class modality, the system bypasses the “text tax” the latency and cost associated with translating everything into an intermediate text representation.
Connection Interfaces and Architectural Overlays in the Realtime API
To bring these multimodal capabilities to developers, OpenAI has structured its Realtime API around a set of distinct connection methods tailored for different operational environments. The architecture is categorized into connection interfaces, agent software development kits (SDKs), and management layers that ensure security and session continuity. For browser-based and mobile applications, WebRTC is the primary standard, offering low-latency media streaming and built-in handling of complex networking challenges like Network Address Translation (NAT) traversal.
Realtime API Connection Methods Comparison
| Interface | Transport Protocol | Primary Application Environment | Latency Characteristics |
| WebRTC | UDP-based (SRTP) | Client-side, browsers, mobile devices | Lowest; optimized for jitter and packet loss |
| WebSocket | TCP-based (TLS) | Server-side, middle-tier applications | Moderate; relies on consistent network reliability |
| SIP | VoIP Standards | Telephony, PBX, and legacy voice systems | Variable; depends on carrier and trunking |
The Realtime API also introduces high-level abstractions through the Agents SDK, which utilizes RealtimeAgent and RealtimeSession modules to automate microphone and audio output connections. On the backend, session management is handled via specialized guides that track the session lifecycle, ensuring that conversation items are properly synchronized through delta events like response.output_text.delta and response.output_audio.delta. For client-side security, OpenAI utilizes an ephemeral key system, where a backend server generates short-lived tokens via a REST API endpoint (POST /v1/realtime/client_secrets), allowing browsers to initialize peer connections without exposing permanent credentials.
The Landscape of Future AI in Development
The current trajectory of technological advancement focuses on how to use ai in development while remaining cognizant of the risks of ai in development, such as model drift and adversarial attacks. Professionals frequently query ai in development news and monitor the ai in development sector to understand what follows agentic ai in development and what comes after agentic ai in development, specifically as it pertains to ai in development finance news. By analyzing what comes after agentic ai in development trends, it becomes clear that what will follow agentic ai in development is a transition toward innovator-level systems that contribute natively to human knowledge.
The progression of AI toward these advanced stages is benchmarked by a five-level roadmap that begins with conversational chatbots and culminates in organizations run entirely by AI. We are currently witnessing the shift from Level 2 (Reasoners) to Level 3 (Agents), where systems are no longer merely reactive but can take proactive, autonomous actions over extended periods. This transition is critical because agents require a different underlying infrastructure than simple chatbots—one that supports long-lived state, multi-step planning, and the ability to interact with external tools through protocols like the Model Context Protocol (MCP).
OpenAI’s Five Levels of AGI Progress
| Level | Designation | Capability Description | Real-World Analog |
| Level 1 | Chatbots | Natural language interaction | ChatGPT, Siri, Alexa |
| Level 2 | Reasoners | Human-level problem solving | PhD-level reasoning models (o1-series) |
| Level 3 | Agents | Autonomous action over days | AI software engineers (e.g., Devin) |
| Level 4 | Innovators | Generation of new ideas/inventions | AI-driven drug discovery, new physics |
| Level 5 | Organizations | AI-run entire organization | CEO-level AI managing strategy/execution |
Optimizing Infrastructure Resilience through Website Maintenance Services
Ensuring the scalability and reliability of these advanced systems on platforms like https://thesoftix.com requires the implementation of comprehensive Website Maintenance Services, which transition from reactive troubleshooting to proactive, AI-driven interventions. Maintaining a high-traffic AI application is a multi-layered challenge that involves continuous monitoring, performance optimization, and rigorous security protocols. Neglecting these services can lead to catastrophic consequences, including lost revenue, negative SEO impact, and severe downtime during traffic surges.
Predictive maintenance is a particularly innovative application in this domain. By leveraging machine learning, systems can analyze traffic patterns to predict server overloads or identify potential plugin and theme failures before they escalate. This proactive stance is essential for AI voice applications, where a single second of latency can disrupt the entire user experience. Maintenance tasks must include regular clean-ups of database indexes to improve speed, automated security rule updates to block malware in real-time, and mobile responsiveness audits to ensure a seamless experience across all devices.
Traditional vs. AI-Powered Maintenance Comparison
| Maintenance Aspect | Traditional Approach | AI-Powered Approach |
| Updates | Manual; scheduled downtime | Automated; continuous integration |
| Troubleshooting | Reactive; fixed after the crash | Proactive; predictive failure analysis |
| Security | Periodic vulnerability scans | Real-time threat detection and blocking |
| Monitoring | Human-led periodic checks | 24/7 automated anomaly spotting |
| Scalability | Manual resource provisioning | Dynamic auto-scaling based on demand |
The Mathematical and Systems Engineering of LLM Inference
At the heart of OpenAI’s delivery mechanism is a highly optimized inference stack. Scaling real-time LLM inference is fundamentally different from scaling traditional web services. While web services are often stateless and CPU-bound, LLM inference is stateful and primarily memory-bound. The performance of the system is dictated by the interaction between the GPU’s high-bandwidth memory (HBM) and the matrix multiplication (GEMM) operations required by the transformer architecture.
To overcome these physical limitations, OpenAI utilizes PagedAttention, a breakthrough in memory management that allows the KV cache to be stored in non-contiguous pages. This eliminates the problem of memory fragmentation, which previously caused frequent “Out of Memory” (OOM) errors in production systems. By managing memory like a virtual operating system, OpenAI can maintain dynamic batching, where requests are added or removed from the GPU’s processing queue in real-time, maximizing throughput without sacrificing latency.

Inference Infrastructure Requirements for Scale
| Resource Type | Specification for 1,000+ Concurrent Calls | Operational Role |
| GPU Cluster | NVIDIA A100 or H100 | Model inference and matrix math |
| CPU Resources | 16-32 cores per node | Audio orchestration and WebRTC |
| Memory (RAM) | 64-128 GB per server | Managing multiple concurrent sessions |
| Storage | SSD-based “hot” storage | Active session data and KV cache |
| Network | 100 Mbps per 100 concurrent calls | Media streaming and signaling |
WebRTC at Global Scale: Rearchitecting for Hundreds of Millions
To maintain global reach for its user base, OpenAI had to re-engineer the standard WebRTC protocol to fit a high-density, containerized environment like Kubernetes. Standard WebRTC often uses a “one-port-per-session” model, which is unsustainable at the scale of 900 million users. OpenAI’s solution was the implementation of a “split relay plus transceiver” architecture.
In this model, the transceiver is the only service that owns the session state, including the DTLS (Datagram Transport Layer Security) handshake and the SRTP (Secure Real-time Transport Protocol) encryption keys. The transceiver service handles two critical jobs: signaling (SDP negotiation and codec selection) and media termination. The relay service, conversely, acts as a high-performance packet forwarder. By separating these concerns, OpenAI can scale the relays horizontally across geographical regions while keeping the complex session logic centralized in the transceivers.
The routing logic is particularly elegant. Instead of a “hot-path” database lookup for every incoming media packet, the system routes based on the ICE ufrag (username fragment), which is a unique string present in every WebRTC connection. This allows the relay to steer packets to the correct transceiver instance with minimal overhead. Furthermore, the relay implementation in Go uses techniques like SO_REUSEPORT, thread pinning, and low-allocation parsing to achieve high performance without the need for complex kernel bypass methods.
Economic and Financial Structural Transitions Driven by Generative and Agentic AI
The rapid deployment of low-latency voice and agentic systems is not just a technical feat; it is a macro-economic event. The IMF and the World Bank have characterized the rise of AI as a “macro-critical transition,” one that has the potential to restructure the global economy. In the financial sector, AI adoption is being led by fintech companies, which are currently outpacing traditional incumbents in the transition to “scaling” and “transforming” stages of AI maturity.
According to the 2026 Global AI in Financial Services Report, 81% of firms are now adopting AI, with agentic AI becoming the clearest growth frontier. Use cases are shifting from simple internal process automation to sophisticated front-office applications like AI-powered customer support and real-time fraud prevention. However, this adoption is uneven. High-income countries are pulling ahead, while emerging market and developing economies (EMDEs) face significant challenges in building the necessary “Four Cs”: connectivity, compute, context, and competency.
Global AI Investment and Usage (2024-2025 Snapshot)
| Metric | United States | China | United Kingdom |
| Private AI Investment | $109.1 Billion | $9.3 Billion | $4.5 Billion |
| Organization AI Usage | 78% | 83% (Sentiment) | 36-39% (Optimism) |
| Model Production (2024) | 40 Notable Models | 15 Notable Models | 3 (Europe Total) |
The financial stability implications are profound. As institutions become increasingly reliant on third-party cloud services and complex, opaque AI models, new risks emerge. The OECD has warned that high concentrations of AI model providers could create systemic vulnerabilities. Regulators are now focusing on “SupTech” (supervisory technology), using AI to identify “mule accounts,” analyze risk management documents, and predict liquidity problems in real-time.
Strategic Governance and Security in the Age of Autonomous AI
As AI agents begin to take independent actions such as executing financial trades or managing logistics the need for robust governance and security becomes paramount. The “Responsible AI” (RAI) ecosystem is evolving to include standardized evaluations for safety and factuality, such as HELM Safety and AIR-Bench. In the United States, the Department of Commerce has struck deals with major players like Google DeepMind and Microsoft to review early versions of new AI models before public release, specifically focusing on national security risks related to cybersecurity and biosecurity.
Security maintenance for these systems involves more than just patching code. It requires protecting the data pipelines against adversarial attacks designed to manipulate AI outputs. For instance, an attacker might attempt to “inject” malicious instructions via a voice signal that is imperceptible to humans but clearly understood by the AI model. To combat this, institutions must implement “secure by design” principles and maintain continuous human oversight over autonomous systems.
The evolution of these systems is also being shaped by geopolitical tensions. U.S. chip export policies have undergone significant adjustments, targeting the ability of competing nations to develop cutting-edge AI. The ban and subsequent reversal on NVIDIA’s H20 chips for the Chinese market illustrate the delicate balance between security interests and economic interests. Meanwhile, open-source models like DeepSeek-R1 are disrupting the market by providing high-performance reasoning capabilities at zero cost, allowing organizations to maintain greater control over their own data and infrastructure.
Synthesis of Technical Innovations and Future Projections
The technical delivery of low-latency voice AI at scale is the result of a coordinated breakthrough across multiple domains: neural architecture, high-performance networking, and proactive systems maintenance. By moving away from the cascaded pipeline model toward a unified multimodal transformer, OpenAI has fundamentally altered the physics of human-AI interaction. The transition from reasoners to agents marks the next great frontier, where AI will shift from being a tool for individuals to a system that executes on behalf of organizations.
For platforms like thesoftix.com, the lesson is clear: success in the AI-driven future requires an unwavering commitment to infrastructure excellence. This includes not only the deployment of the latest models but also the rigorous application of Website Maintenance Services to ensure that these systems remain performant under global load. The challenges ahead ranging from memory bandwidth bottlenecks and KV cache fragmentation to global regulatory compliance and adversarial security are significant. However, the roadmap provided by OpenAI’s five levels of progress offers a structured path forward, leading toward a world where AI is as versatile, creative, and independent as human intelligence.
As we look toward 2026, the focus will increasingly shift toward “Small AI” for efficiency, “Agentic AI” for autonomy, and “Responsible AI” for safety. The ability to deliver these services at scale, with sub-250ms latency, will remain the gold standard for the industry, driving innovation across finance, development, and the broader digital economy. The intersection of technical mastery and strategic foresight will define the winners in this macro-critical transition toward an intelligence-based global infrastructure.


